Introduction
Soybean (Glycine max (L.) Merr.) is the most important legume crop, representing 50% of the global legume crop area and 68% of global legume production (Herridge et al., 2008). Soybean is consumed as health food, providing a rich source of proteins, and as well as vegetative oil production (Messina, 1999; Pimentel and Patzek, 2005). Moreover, soybean plays an important role for dinitrogen (N2) fixation, which is an important natural process (Herridge et al., 2008).
Several diseases in soybean, such as cyst, brown spot, charcoal rot, and sclerotinia stem rot, lead to yield losses in major soybean-producing countries (Wrather et al., 2001). In addition, soybean can be infected by diverse viruses. Although a small numbers of viruses infecting soybean cause serious economic problems in soybean production, it is always important to control and to manage viral diseases in soybeans (Hill and Whitham, 2014). The best known soybean virus is Soybean mosaic virus (SMV), a member of the family Potyviridae, causing soybean mosaic disease. In addition, bean pod mottle virus (BPMV), soybean vein necrosis virus, tobacco ringspot virus, soybean dwarf virus, peanut mottle virus, peanut stunt virus, and alfalfa mosaic virus are important viruses infecting soybeans (Hill and Whitham, 2014).
Many plant viruses have been identified based on viral disease symptoms and several detection methods. However, virus infection in plants does not always cause disease symptoms, and many plants showing viral disease symptoms are very often co-infected by different viruses. Recent advances in next generation sequencing (NGS) technology lead to identification of numerous known as well as novel viruses by means of metagenomics (Barba et al., 2014; Massart et al., 2014). Not only NGS data for virus detection but also many plant transcriptome data contain virus sequences, which might be amplified along with infected host transcripts (Burger and Maree, 2015; Jo et al., 2016). The identification of virus sequences in the plant transcriptome is no longer surprising, because most plant viruses are RNA viruses and many of them carry poly(A) tail, which is easily amplified by oligo d(T) primers for cDNA synthesis.
Recently, we carried out a large-scale screening to identify viruses infecting soybean in the world using available soybean transcriptome data. Of them, we found that a soybean transcriptome for soybean seed development analysis contains many virus sequences. In this study, we conducted a bioinformatics analyses for virus identification, virus genome assembly, phylogenetic analysis, and single nucleotide variations of the SMV.
Materials and Methods
Plant materials, library preparation, and next generation sequencing
The plant material used for RNA-Seq was soybean cultivar Heinong44. Plants were grown in the experimental station in Beijing from May to August according to the previous study (Song et al., 2013). Total RNAs were extracted from seeds at six different developmental stages, which were classified according to the seed weight. The cDNA was synthesized using poly(A)-containing RNAs. A single RNA-Seq library was constructed and sequenced by single-end sequencing using the Illumina HiSeq 2000 system. The raw data is available in the SRA database (http://www.ncbi.nlm.nih.gov/sra/SRR1777405).
Raw data processing and de novo transcriptome assembly
All bioinformatics analyses were performed in the Linux (Linux Mint version 17)-installed workstation (four 16-core CPUs and 256 GB ram). We downloaded the raw data from the SRA database using the SRA toolkit (Leinonen et al., 2011). The raw SRA data were converted to FASTQ files using the SRA toolkit. For the de novo assembly of transcriptomes, we used Trinity version 2.0.6 (Haas et al., 2013). De novo transcriptome assembly was performed according to the manuals provided by developers with default parameters.
Identification of viruses and sequence alignment
To identify virus-associated contigs, we conducted blast search using standalone BLAST version 2.1.19 installed in the Linux system (Madden, 2013). All assembled contigs were subjected to MEGABLAST search, which is optimized for highly similar sequences, against complete reference sequences for viruses and viroids (http://www.ncbi.nlm.nih.gov/genome/viruses/) with E value 1e-5 as a cutoff. In addition, all raw data were converted to FASTA files using the SRA toolkit and subjected to a MEGABLAST search against the viral reference database with E value 1e-5 as a cutoff. We used the Burrows-Wheeler Aligner (BWA) software for sequence alignment on the reference virus genome with default parameters (Li and Durbin, 2009).
De novo assembly of SMV genomes
The 79 SMV-associated contigs identified by the BLAST were retrieved by the BLASTCMD program in the standalone BLAST system. To assemble SMV genomes, the identified viral contigs were aligned against the SMV reference genome (NC_002634.1) using ClustalW implemented in the MEGA6 program (Tamura et al., 2013) The nearly complete consensus genome of SMV was manually obtained. Raw data were again aligned on the assembled consensus SMV genome to confirm sequences by BWA. The poly(A) tail at the 3′ end of the assembled SMV genome was removed. We obtained a nearly complete consensus genome for SMV China (accession number NC_002634.1) from soybean transcriptome.
Identification of SNVs in soybean transcriptome
In order to analyze SNVs of SMV China in the soybean transcriptome, the raw data were aligned on the consensus genome of SMV China using the BWA program with default parameters. The aligned SAM files by BWA were converted into BAM files by SAMtools (Li et al., 2009). For SNV calling, we sorted the BAM files and then generated the VCF file format using mpileup (Danecek et al., 2011). BCFtools implemented in SAMtools was finally used to call SNVs. The positions of identified SNVs on the SMV genome were visualized by the Tablet program (Milne et al., 2010).
Construction of phylogenetic trees
In order to reveal phylogenetic relationships of the obtained consensus genome for SMV China with known SMV isolates, we generated three phylogenetic trees. The complete SMV isolate China genome sequence as well as two polyprotein sequences were blasted against NCBI nucleotide and non-redundant protein databases. Best-matched sequences were retrieved for the construction of phylogenetic tree. The obtained sequences were aligned by the ClustalW program with default parameters. After alignment, we deleted unnecessary sequences. The manually edited aligned sequences were subjected to construction of a phylogenetic tree using the MEGA6 program. The phylogenetic tree was constructed by the neighbor-joining method, with 1,000 bootstrap replicates.
Results
De novo soybean transcriptome assembly and identification of viruses in the soybean seeds
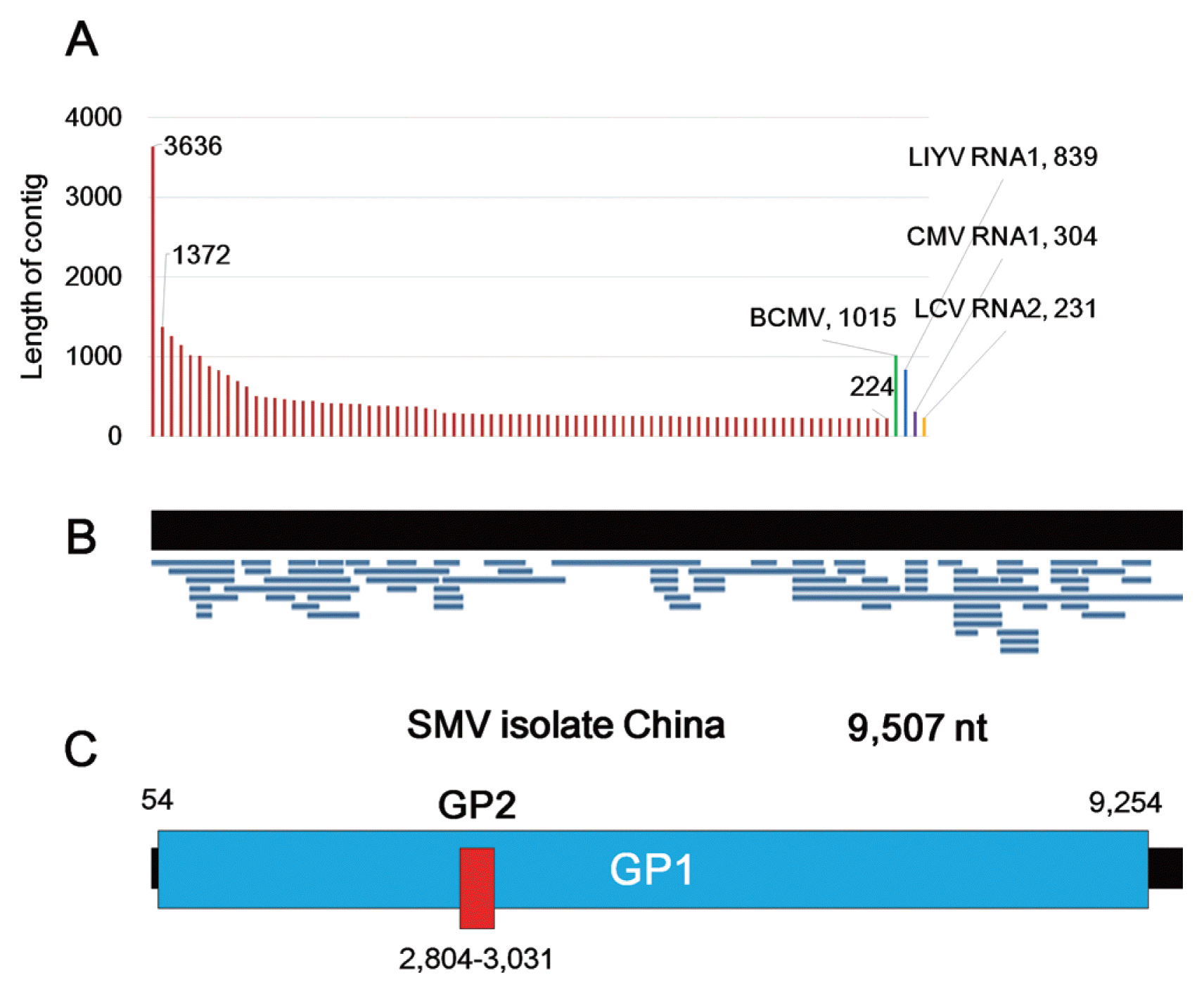
We screened available soybean transcriptome data deposited in NCBI’s Sequence Read Archive (SRA) database in order to identify viruses infecting soybean. Of screened soybean transcriptomes, a transcriptome conducting a gene expression profile during soybean seed development contains several virus-associated sequences (accession number SRR1777405) (Song et al., 2013). In order to identify virus-associated contigs, we de novo assembled the transcriptome of soybean using Trinity program, resulting in 116,108 transcripts (contigs) with 710 bp for contig N50 (Table 1). Next, we blasted 116,108 transcripts against the viral reference database. After removing redundant sequences and endogenous viral sequences, we identified 83 contigs-associated with viruses (Table 2). Most contigs (79 contigs) were associated with SMV. The lengths of SMV-associated contigs ranged from 224 to 3,636 nt (Fig. 1A). Four contigs were associated with BPMV, lettuce infectious yellow virus (LICV), lettuce chlorosis virus (LCV), and cucumber mosaic virus (CMV), respectively. The lengths of contigs associated with the four viruses ranged from 232 nt (LCV RNA2) to 1,015 nt (bean common mosaic virus) (Fig. 1A). Other than a contig-associated with LICV (1E-08), virus-associated contigs display reliable E values indicating significance of blast results (Table 2).
De novo genome assembly of SMV from a soybean transcriptome
Of identified viruses, SMV was severely infected in the soybean seeds. Fortunately, 79 contigs associated with SMV mostly covered the SMV reference genome (Table 2). A total of 79 contigs associated with SMV were mapped on the SMV reference genome (accession number NC_002634.1) (Eggenberger et al., 1989) (Fig. 1B). After sequence alignment followed by manual modification, we assembled a nearly complete consensus genome of SMV referred as SMV China (Fig. 1C). The SMV China is composed of 9,507 nucleotides (nt) encoding two proteins such as GP1 and GP2. GP1 encodes a polyprotein (nt 54 to 9,254) which is further cleaved into ten mature proteins such as P1 (P1 proteinase), HC-Pro (helper component proteinase), P3 (P3 protein), 6K1 (6K1 protein), CI (cylindrical inclusion), 6K2, NIa-VPg (Nuclear inclusion protein a-genome linked viral protein), NIa-Pro, NIb (nuclear inclusion protein b), and coat protein (CP) while GP2 encodes PIPO (pretty interesting potyviridae ORF) protein (nt 2,804 to 3,031) (Fig. 1C).
Phylogenetic relationships of the SMV isolate China
In order to find genetic relationships of the assembled SMV China with known SMV isolates, we constructed phylogenetic trees. The phylogenetic tree using SMV complete genome sequences showed two groups of SMV isolates (Fig. 2A). The SMV China belongs to group B along with two SMV isolates from South Korea. Using polyprotein sequences, the SMV China in group C was distantly related with other SMV isolates (Fig. 2B). The phylogenetic tree using PIPO protein sequences confirmed that SMV China is a member of SMV belonging to group A, which contains seven viruses including BPMV (Fig. 2C). Based on phylogenetic analyses, it seems that the consensus genome of SMV China is genetically close to the SMV isolates from South Korea.
Single nucleotide variations of SMV in the soybean seeds
It is well known that RNA viruses exhibit quasispecies nature, exhibiting several variants in the infected host. Therefore, we examined single nucleotide variations (SNVs) for SMV in the soybean seeds. The identified SMV China was used as a reference. After BWA alignment of raw data against SMV China, SNVs were identified using SAMtools (Fig. 3A). The SNVs in this study was derived from a population of different isolates. As a result, we identified 780 SNVs (Supplementary Table 1). SNVs were evenly distributed along the SMV genome (Fig. 3B). Most SNVs were Single nucleotide polymorphisms (SNPs) except one InDel (CAGG to CAGGAGG) at nt 640 of SMV China (Table S1). Four SNVs, C-U (190 SNVs), U-C (180 SNVs), A-G (168 SNVs), and G-A (155 SNVs), were frequently identified (Fig. 3C). Based on SNV results, the mutation rate for SMV in the soybean seeds was 8.2045%, indicating a high level of mutations for the SMV RNA genome. In addition, we calculated the ratio of Ts/Tv (Transition versus Transversion). The Ts/Tv ratio for SMV China was 8.06 (693/86).
The amount of viral RNA in the soybean transcriptome
It might be of interest to examine viral RNAs in the analyzed soybean transcriptome. Of 116,108 contigs, virus-associated contigs account for 0.068% (79 contigs). The length of total assembled contigs was 67,363,642 bp and the total length of virus-associated contigs 36,022 bp, accounting for 0.0535%. The amount of virus-associated reads accounts for 0.0529% (39,403/74,431,152) of reads. Moreover, we calculated SMV copy numbers within the soybean transcriptome resulting in 414 SMV virus copies, which is highly correlated with sequence coverage of SMV genome. This result indicates high variability of SMV genome.
Discussion
Development of NGS provides various DNA as well as RNA sequencing data (Metzker, 2010). The main purposes of DNA and RNA sequencing is elucidation of the genome and transcriptome of target eukaryotic and prokaryotic organisms (Morozova and Marra, 2008). In case of bacteria, metagenomics using 16s rRNA sequences that are highly conserved in bacteria species is intensively performed to study bacterial communities under specific conditions (Wang and Qian, 2009). However, viruses do not have any conserved sequences like bacteria, and genomes of viruses are mostly very small (Edwards and Rohwer, 2005). Therefore, virus-specific sequencing usually requires a purification step for NGS. For example, extraction of double-stranded RNAs from virus-infected organisms followed by NGS is one of the efficient approaches to identify viruses (Yanagisawa et al., 2016). Moreover, sequencing of small RNAs is an alternative technique for virus identification and genome assembly (Vodovar et al., 2011). In addition, RNA-Seq is also a good technique to identify viruses that have a poly(A) tail. However, several recent studies demonstrated that viruses and viroids without a poly(A) tail can be detected by RNA-Seq (Burger and Maree, 2015; Jo et al., 2016).
In this study, we identified several viruses infecting soybean. This transcriptome was initially conducted for expression profiling of soybean seed development. Thus, this transcriptome is not derived from a single condition but from six developmental seed stages in which several seeds might be included for total RNA extraction. Although we identified five viruses that might infect soybean, four viruses other than SMV were identified based on only one single contig, and their presence should be validated by other methods. In many cases, the partial viral sequence or contig is homologous to a closely related virus, not the target virus. Thus, it is possible that the identified virus-associated contigs might be not from the infected viruses but from other viruses which share similar viral sequences.
SMV is seed-borne and transmitted by aphids (Domier et al., 2011). Soybean seeds infected by SMV often display a discolored and mottled seed. In addition, BCMV is known as a seed-borne virus (Refugee et al., 1987). Seed-borne viruses can be actually infected in embryo, such as BCMV, or carried on the seed coat (Jafarpour et al., 1979). In addition, seed transmission of CMV has been identified in several plants such as pepper, spinach, and lupin (Ali and Kobayashi, 2010; Wylie et al., 1993; Yang et al., 1997). Based on previous knowledge on seed-borne viruses, the identification of SMV, BCMV, and CMV in the soybean seed is not surprising. In addition, the infection of LCV in green bean (Phaseolus vulgaris L.) has been recently reported (Ruiz et al., 2014). However, the infection of LIYV and LCV, which are members in the genus Crinivirus, in the soybean seed should be validated.
The soybean transcriptome was derived not from a single soybean seed but from a mixture of soybeans which were further divided into six developmental stages of seeds. The lengths of assembled contigs-associated with SMV in this study might be shorter than virus-associated contigs from a single plant due to the transcriptome containing several variants of SMV. Therefore, the assembled genome of SMV China is a consensus sequence of several SMV variants. Although the portion of SMV-associated sequences accounted for about 0.05% in the total transcriptome, the coverage of SMV genome in this study was about 414, and its coverage was also visualized by the alignment of raw data on the genome of SMV China. As a result, we could de novo assemble SMV genome based on enough sequence data associated with SMV.
Based on the assembled SMV genome, we could also identify SNVs for SMV. As we expected, we found several SNVs that resulted from a mixture of SMV infected diverse seed samples. However, we could not reveal the exact number of variants. Furthermore, the identification of SNVs in SMV demonstrated that not a specific region of SMV but several regions of SMV genome were highly mutated. The presence of several SMV variants in the soybean seeds is a very interesting finding, indicating that SMV is highly replicated in the developing seeds; this might be correlated with some disease symptoms in the soybean seeds caused by SMV. It might be of interest to examine replication rates of SMV in different developmental stages and tissues; this could provide evidence of the quasispecies nature of SMV in the near future.
Phylogenetic analyses suggested that the identified SMV isolate China was very different from other known SMV isolates based on polypeptide sequences. However, SMV isolate China seems to be highly correlated with two SMV isolates from South Korea, suggesting the phylogenetic correlation between geographical regions and SMV isolates.
Our SNV analysis in the soybean seeds indicates a high level of quasispecies nature for SMV. Mutations were not in a specific region but in most regions of SMV genome. Furthermore, we found that A-G and C-U conversions and vice and versa were frequent.
Taken together, our bioinformatics analyses using soybean seed transcriptomes identified five viruses infecting the soybean seeds. Of these five viruses, we de novo assembled the genome of SMV isolate China and analyzed SNVs revealing quasispecies nature of SMV in the soybean seeds for the first time. Our approaches and analyses in this study are valuable for the virus-associated studies using NGS-based transcriptome data.


 PDF Links
PDF Links PubReader
PubReader Full text via DOI
Full text via DOI Full text via PMC
Full text via PMC Download Citation
Download Citation Supplement
Supplement Print
Print